
Misconfigured NGINX worker_connections caused downtime

Today, we're diving into a recent downtime incident I faced on my web app. My web app is a multi-tenant ecommerce application that provides webshops for restaurants and snackbars, kinda like Shopify on a smaller scale. It’s mainly powered by a Laravel monolithic application.
We have a pretty predictable traffic pattern, with 1 spike around lunch time, and a bigger spike around dinner time.
At the time of the incident, we had an infrastructure that looked a little something like this:
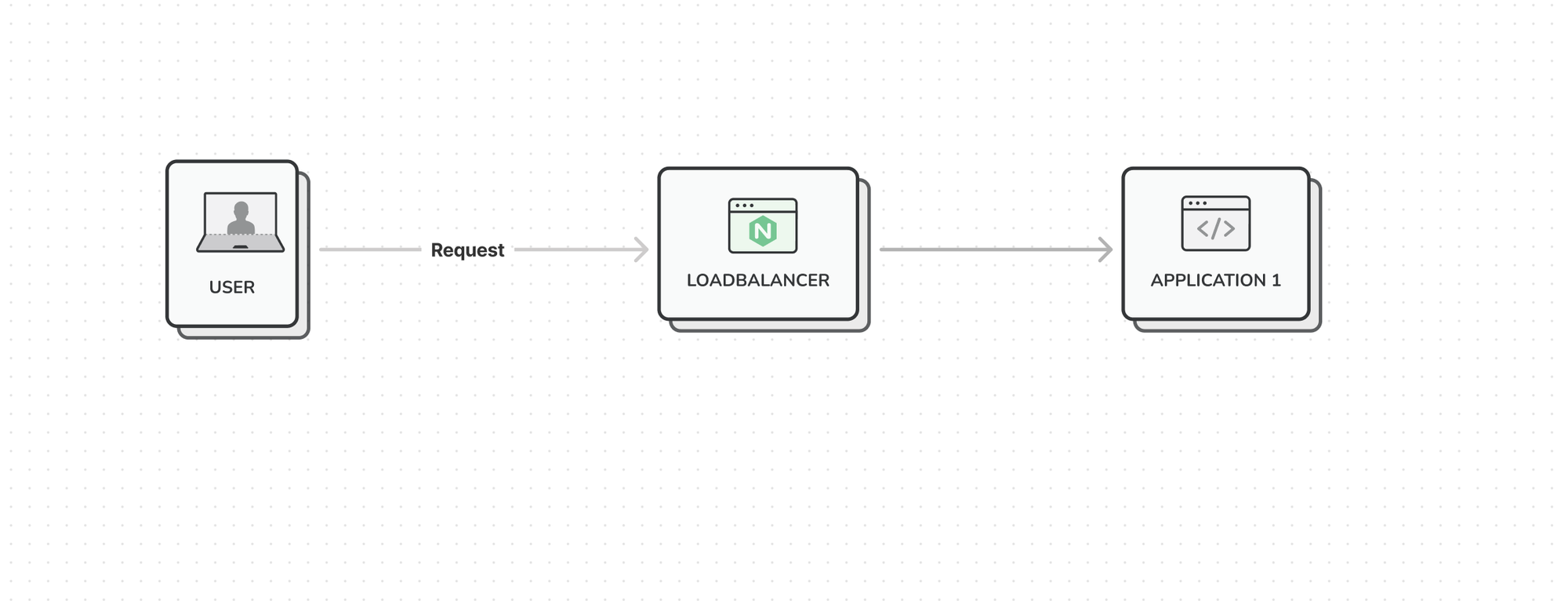
Whenever a request comes in, we had 1 application server that would handle all the traffic, and we already had a loadbalancer in between for easy horizontal scaling.
The incident
Despite monitoring our system's health, which showed low CPU usage across the board, we were caught off guard on a friday evening when our services suddenly went dark. Friday evenings at around 6pm are the busiest time of the week on our platform because that’s when everyone starts ordering their dinner.
In an attempt to mitigate this problem, I scaled our service horizontally and added 2 more application servers. Luckily - we had already configured our loadbalancer, our DNS records were already set up correctly and assets were already being hosted on S3 and served by CloudFront. So adding 2 application servers was a breeze:
- We spin up and provision a new machine
- We configure our application
- We add it to the load balancing pool
Now we have an infrastructure that looks like this:
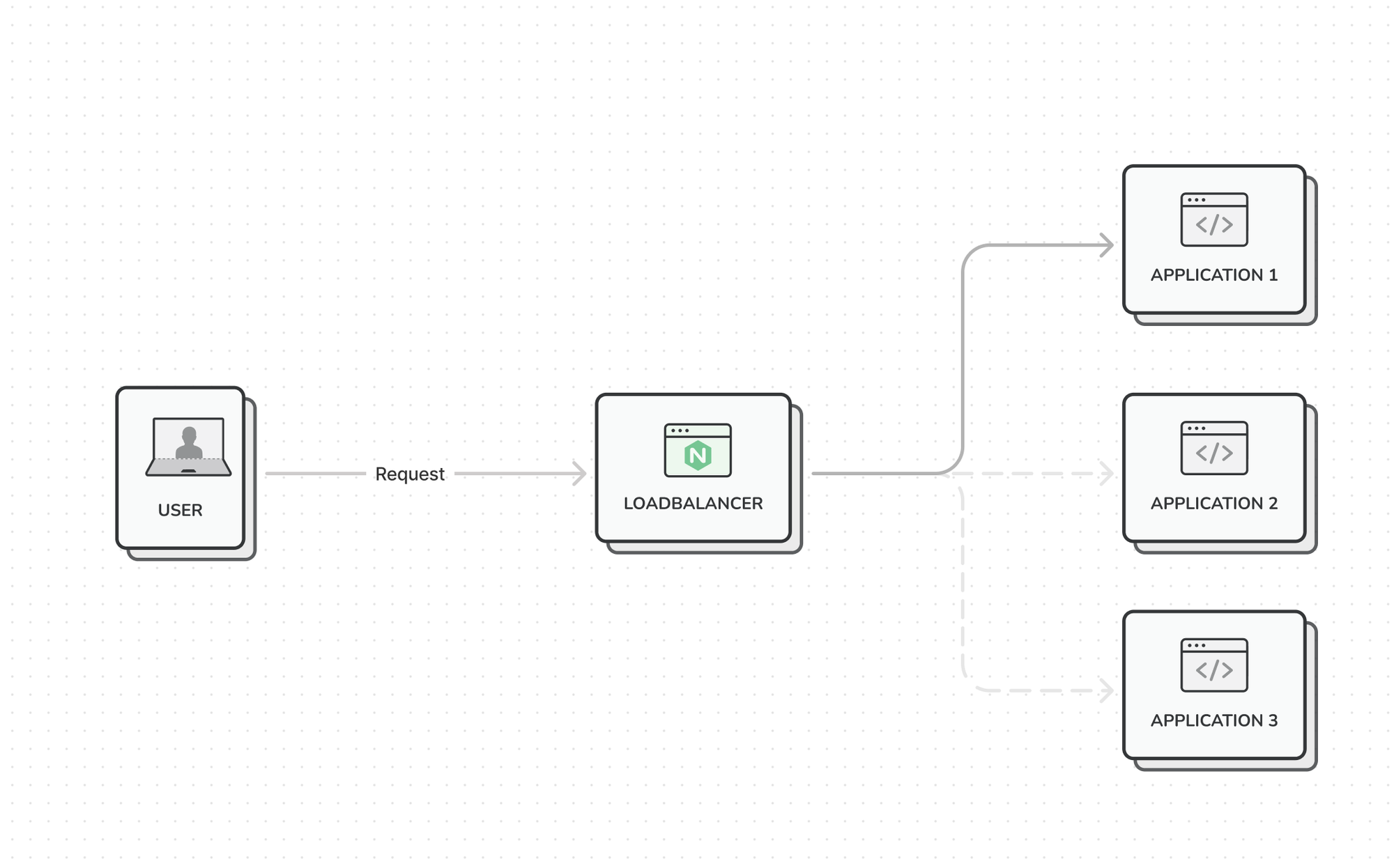
When a user-request comes in, the loadbalancer would talk to the pool of application servers in a round-robin fashion. The first request would end up at application 1, the second on application 2, and the third on application 3.
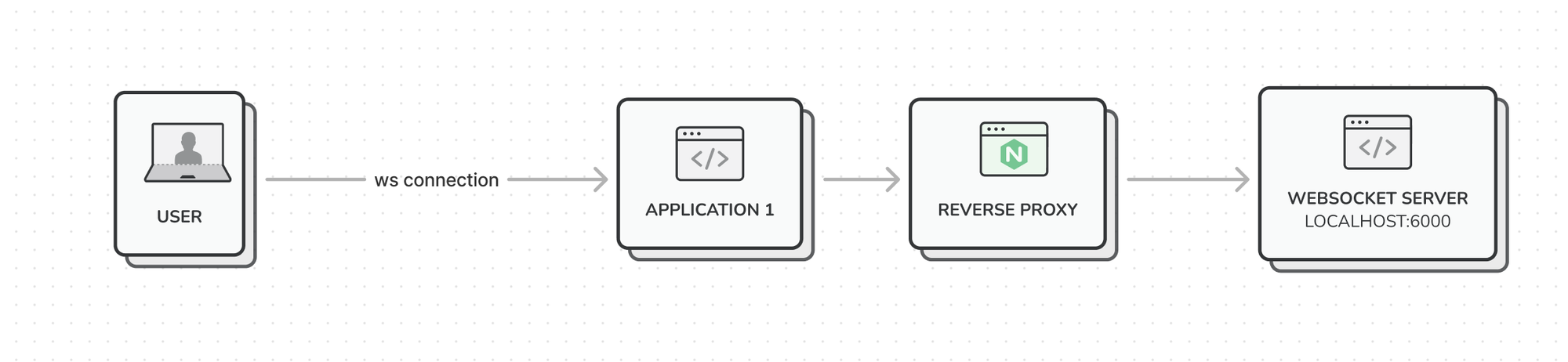
An important detail to note is that on Application 1 server we were also running a websocket server to offer some realtime functionalities to our merchants, so when a customer places an order, their application would instantly pick it up. This websocket server sat behind an NGINX reverse-proxy.
Uncovering the root cause
In our quest to uncover the root cause, I initiated a thorough investigation - I HAD to get to the bottom of this.
My first instinct was to log in to the server and check for 502 gateway timeout errors because of a misconfiguration on PHP-FPM. To my surprise however, there were no such errors being reported in our application server logs.
Next thing I did was log in to our NGINX Amplify dashboard and on our LoadBalancer instance we were in fact seeing a spike in 502 gateway timeout errors.
Our application server however did not report any 502 gateway timeout error, which made me suspect nginx itself was throwing an error. And when NGINX itself throws an error, we don’t get a 502 gateway timeout error, but instead we get a 500 internal server error.
After I realised this, I opened the logs again and searched for internal errors and behold, I had found the culprit! The error read:
512 worker_connections are not enough while connecting to upstreamI went to the nginx docs to read up about this parameter, and by default this was configured to 512.
Because of our many simultaneous websocket connections, we were effectively hitting the 512 limit, and NGINX was not configured to increase the worker_processes, so when our application server would hit this limit, it stopped accepting any new incoming requests.
I resolved this by increasing our worker_connections to 768 and I changed the worker_processes configuration from 1 to auto, so nginx would add extra workers if needed.
worker_processes auto;
events {
worker_connections 768;
}And we haven’t faced a similar issue since! And we could actually undo our 2 application servers in an effort to reduce monthly costs.
Lessons learned
Here are a couple of lessons learned when facing this situation:
Number 1 - Separations of concern
If we had hosted our websocket server on a different machine, our impact would’ve been greatly reduced. We would have still hit the worker_connections error, but instead of impacting the entire application server, the impact would’ve been scoped to the websocket machine.
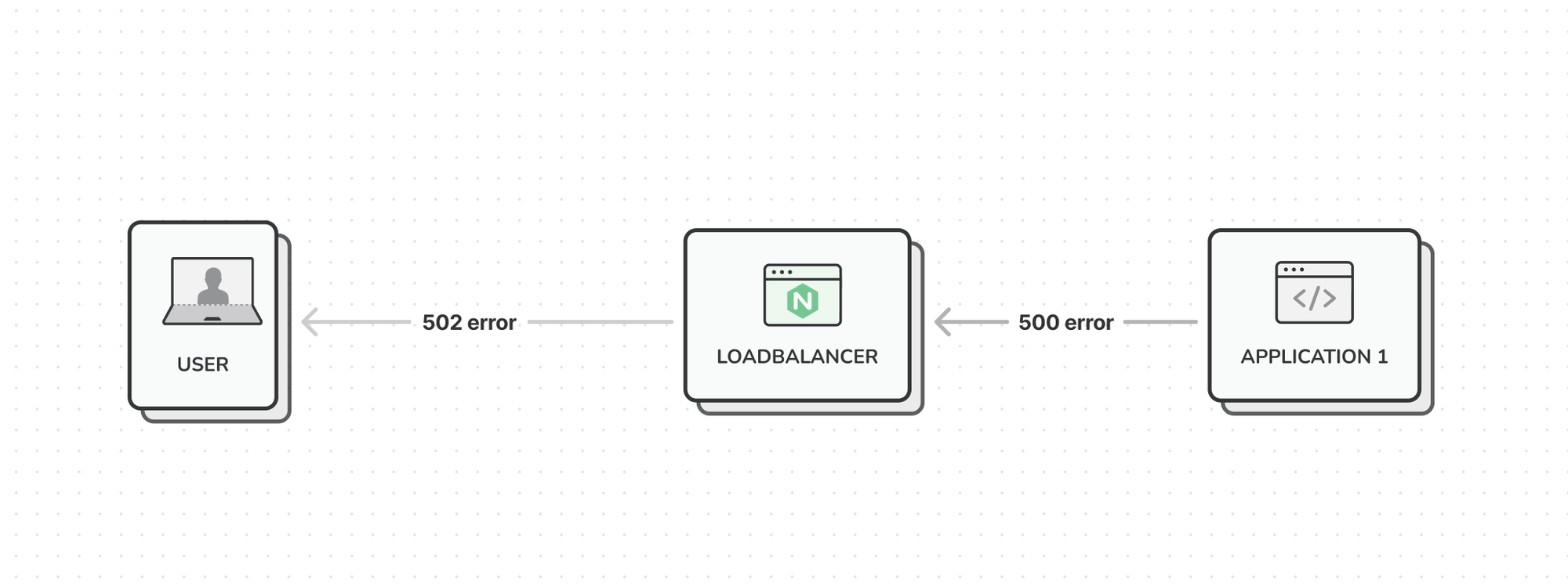
Number 2 - 502 vs 500 errors
This one may seem obvious, but it can be a bit confusing at first. When your application server responds using a 500 error, your loadbalancer will respond with a 502 error.
Number 3 - Have a loadbalancer configured before you feel the need to scale
When we faced our downtime, the thing that saved us was having a loadbalancer configured so we could easily add extra application servers.
And finally lesson number 4 - Tweak the default configuration
NGINX ships with sensible defaults, but when your platform starts to grow, you can easily outgrow these defaults. Spend some time reading up on the default configuration, and tweak it to your specific needs.
That concludes the lessons learned, I hope you gained a few insights 🙌
No spam, no sharing to third party. Only you and me.